"The alleged opinion that studies in seminars [in classes] are of the highest scientific nature, while exercises in solving problems are of the lowest [rank], is unfair. Mathematics to a considerable extent consists in solving problems, [and] together with proper discussion, [this] can be of the highest scientific nature while studies in ... seminars might be of the lowest [rank]."
Source: http://www.sciencedirect.com/science/article/pii/S0024379504000357
Monday, November 05, 2012
Sunday, July 01, 2012
NIST Bigdata workshop
Facebook generates user logs of size 130TB/day and
pictures of size 300TB/day. Google generates >25PB/day of processed
data. Bigdata is about storage, processing and analysis of large amounts of data.
In this NIST organized one and a half day bigdata
workshop, many stalwarts of computing along with other industry representatives
came together to present and discuss the current infrastructure, technology
and solutions in the bigdata space. Several people were invited to give talks (http://www.nist.gov/itl/ssd/is/upload/BIG-DATA-Workshop-may25.pdf
) Talks that I found interesting in the workshop were given by these people:
Ian Foster
is a Distinguished Fellow and the Associate Division Director in the
Mathematics and Computer Science Division at Argonne National Laboratory, where
he leads the Distributed Systems Laboratory. He is known as the ‘father of the
grid’. He described the Globus(GT) project
that has been developed since the late 1990s to support the development of
service-oriented distributed computing applications and infrastructures. Core
GT components address, within a common framework, basic issues relating to
security, resource access, resource management, data movement, resource
discovery, and so forth. These components enable a broader “Globus ecosystem”
of tools and components that build on, or interoperate with, core GT
functionality to provide a wide range of useful application-level functions.
These tools have in turn been used to develop a wide range of both “Grid”
infrastructures and distributed applications.
M
Stonebraker (developer of the Postgres RDBMS, former
CTO of Informix, founder of several database startups) is a professor of
Computer Science at MIT. Stonebraker has been a strong critic of the NoSQL
movement and suggests that Hadoop based systems are a ‘non-starter’ for bigdata
scientific problems. Hadoop based systems are only useful for embarrassingly
parallel computations (such as parallel grep)
Stonebraker primarily talked about his efforts and
involvement with two projects, VoltDB (commercial startup) and SciDB
(open-source scientific database system).
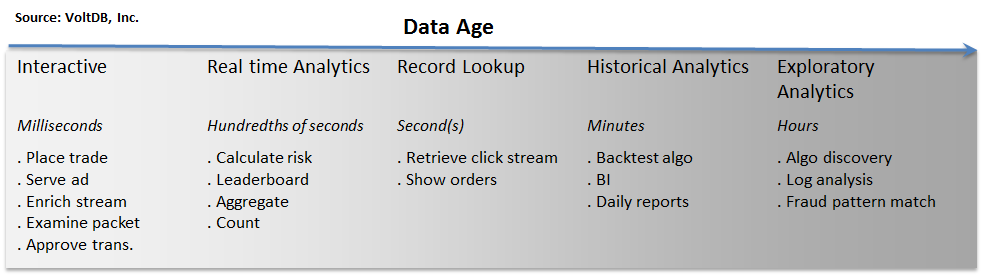
(Age of Data; source: VoltDB)
In the graphic above, time is represented on the
horizontal axis. To the far left is the point at which data is created. The
“things” we do with data are strongly correlated to its age and some usecases
are shown above. Just
after data is created, it is highly interactive. We want to perform high
velocity operations on that data at this stage – how fast can we place a trade,
or serve an ad, or inspect a record? Shortly after creation, we are often
interested in a specific data instance relative to other data that has also
arrived recently – this type of analytics is referred to as real time
analytics. As data begins to age, our interest often changes from “hot”
analytics to record-level storage and retrieval – store this URL, retrieve this
user profile, etc.
Ultimately data becomes useful in a historical context. Organizations have found countless ways to gain valuable insights – trends, patterns, anomalies – from data over long timelines. Business intelligence, reporting, back testing are all examples of what we do to extract value from historical data.
Ultimately data becomes useful in a historical context. Organizations have found countless ways to gain valuable insights – trends, patterns, anomalies – from data over long timelines. Business intelligence, reporting, back testing are all examples of what we do to extract value from historical data.

The above graphic (source: VoltDB) shows different technologies being
used today for different types of application usecases for data value chain.
VoltDB (100x
of standard SQL) is a blazingly fast in-memory relational database management
system (RDBMS) designed to run on modern scale-out computing infrastructures.
VoltDB is aimed at a new generation of high velocity database applications that
require:
·
Database
throughput reaching millions of operations per second
·
On
demand scaling
·
High
availability, fault tolerance and database durability
·
Realtime
data analytics
SciDB is a new open-source data management system
intended primarily for use in application domains that involve very large
(petabyte) scale array data; for example, scientific applications such as
astronomy, remote sensing and climate modeling, bio-science information
management, as well as commercial applications such as risk management systems
in the financial services sector, and the analysis of web log data. SciDB is
not optimized for online transaction processing (OLTP); it only minimally
supports transactions at all. It does not provide strict atomicity,
consistency, isolation, and durability (ACID) constraints. It does not have a
rigidly-defined, difficult-to-modify schema. Instead, SciDB is built around
analytics. Storage is write-once, read-many. Bulk loads, rather than single-row
inserts, are the primary input method. "Load-free" access to
minimally-structured data is provided.
Stonebraker mentioned applications such as high
frequency volume trading, sensor tagging, real time global position assembly as
right candidates for database oriented bigdata problems. These data are good
for cases involving pattern finding in a firehose, complex event processing,
real time complex high performance OLTP as well as data with ‘Big Variety’ (see
Daniel
Bruckner and Michael Stonebraker. Curating Data at Scale: The Data Tamer
System)
Michael
Franklin is a Professor of Computer Science at UC Berkeley,
specializing in large-scale data management infrastructure and applications. He
is the director of AMPLab
(See overview slides here: http://www.scribd.com/doc/58637242/
) at UCB.
Some bigdata projects and systems he mentioned:
Bigdata processing - pregel, dryad, hadoop, M,
hbase, mahout, hypertable, cassandra
Bigdata interfaces: Pig, Hive
AmpLab projects leveraging hadoop for complex
bigdata problems:
Spark – Scala based
Shark – Spark + Hive - lots of caching for
performance gains for iterative machine learning algorithms on big data
He also mentioned AMPCamp being organized on Aug 21-
22 in Berkeley – hands-on tutorial for Shark, Spark and Mesos, machine
learning, crowd sourcing overviews, apps and usecases
Kirk
Borne (George Mason univ) themed his talk around the
following:
- characterize
the known (clustering, unsupervised)
- assign
the new (classification, supervised learning)
- discover
the unknown (outlier, semi-supervised learning)
Dennis
Gannon, Microsoft Research described about their 100
globally dist. data centers, 8-9 public data centers with 1M servers each,
their International Cloud Research Engagement Project for applications such as
Realtime traffic analysis and democratized access to big data. He also
described Microsoft’s SAAS based solution competing with mapreduce/hadoop
called Daytona and the datamarket build around it.
He also mentioned about their efforts to leverage
bigdata and cloud support for MS Excel (some free plugins on MSR site for
working with bigdata directly on Excel!)
Joseph
Helerstein, Computational Discovery Department, Google
described ‘Google Exacycle’ project for Visiting Faculty giving away 1 billion
core-hours for researchers (10 numbers)
Mark
Ryland, Chief Solution Architect, Amazon Web Services gave
some very cool demos demonstrating quick setup and processing for bigdata
problems on Amazon’s cloud infrastructure. He mentioned things such as:
- Taser
– by Police Dept for video storage on the cloud using AWS infrastructure
- S3,
EC2, Relational Data Service infrastructure
- DynamoDB - NoSQL 100Ks of IO/s
- Amazon
Elastic MapReduce (EMR) (used by Yelp - 400 GB of log data per day)
- 1000
genome project - Federal Govt initiative
- BioSense
2.0
- Coursera
site running on AWS
- NYU Langone project
Charles
Kaminski, Chief Architect, LexisNexis also demonstrated
their cloud infrastructure for bigdata problems. (http://aws.hpccsystems.com)
He mentioned LexisNexis projects for scientific computing such as:
- thor
- data crunching
- roxie
- key-value store + complex data process
- ECL
language - transformative data graph used for setting up workflows for thor and
roxie
Ed
Pednault, CTO , Scalable Analytics, Business Analytics and
Math Sciences, IBM Research also mentioned very interesting bigdata work
happening at IBM.
Subscribe to:
Comments (Atom)